

Michele Riva
Algorithms
5
min read
Apr 1, 2023

The Levenshtein edit distance, also known as the Levenshtein distance, is a measure of similarity between two strings, which quantifies the number of single-character edits required to change one string into the other. In this post, we will delve into the details of this algorithm, its applications, and its limitations. We will also explore various implementations and optimizations.
Introduction
The Levenshtein edit distance was developed in 1965 by the Soviet mathematician Vladimir Levenshtein. The algorithm calculates the minimum number of single-character edits (insertions, deletions, and substitutions) needed to transform one string into another. This metric is widely used in various fields such as natural language processing, bioinformatics, data analysis, and search engines.
Algorithm
There are several ways to compute the Levenshtein distance between two strings. We will discuss two popular methods: a naive recursive implementation and a dynamic programming-based implementation.
Naive Recursive Implementation
The naive recursive implementation is based on the observation that the Levenshtein distance between two strings can be defined in terms of smaller substrings. Let’s denote the Levenshtein distance between strings A and B as lev(A, B). The distance can be recursively defined as:
This approach suffers from a high time complexity of O(3^n), making it impractical for long strings.
Dynamic Programming Implementation
The dynamic programming implementation of the Levenshtein distance algorithm, also known as the Wagner-Fisher algorithm, significantly reduces the time complexity by storing intermediate results in a matrix. This method has a time complexity of O(mn), where m and n are the lengths of the input strings.
To compute the Levenshtein distance using dynamic programming, follow these steps:
Create a matrix
Dwith dimensions(m+1) x (n+1), wheremandnare the lengths of the input stringsAandB, respectively. Initialize the first row with values from0tomand the first column with values from0ton.Iterate through the matrix from the second row and second column to the last row and last column. For each cell
(i, j)in the matrixD, compute the costc:
1const c = A[i - 1] == B[j - 1] ? 0 : 1
Update the value of the cell (i, j) with the minimum of the following:
The Levenshtein distance is the value in the bottom-right cell of the matrix D.
Here’s an example to illustrate the algorithm with input strings A = "kitten" and B = "sitting":
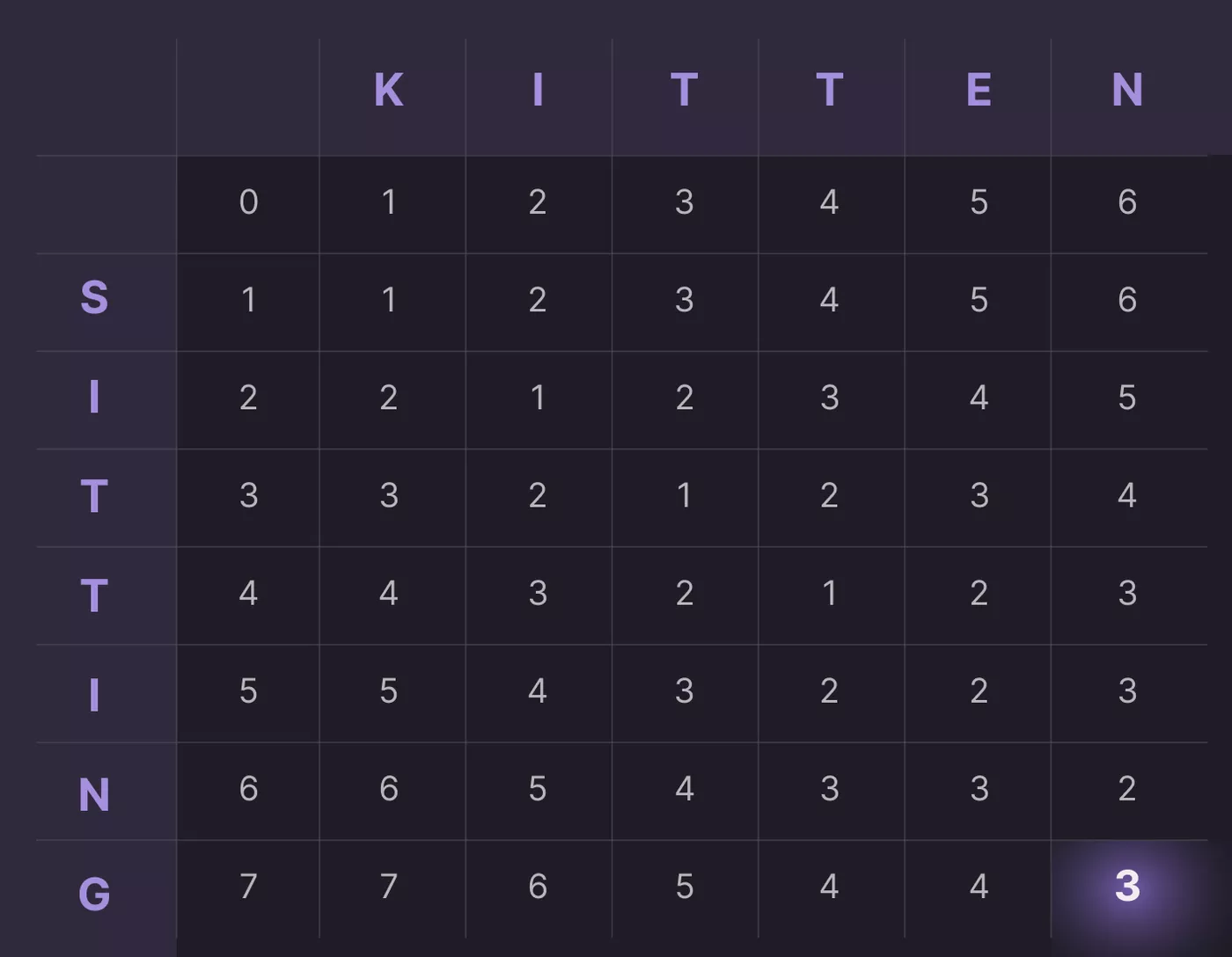
The Levenshtein distance between kitten and sitting is 3, as shown in the bottom-right cell of the matrix.
And here’s a reference implementation of the dynamic programming algorithm written in JavaScript:
Typo tolerance in Orama
Orama supports typo-tolerance thanks to an highly optimized Levenshtein implementation, and can be enabled using the following API:
In that case, it will match all the terms where the edit distance between the term and the indexed words is equal to or less than 1. When searching for "hello, wrld", Orama will be able to understand the typo in "wrld", and will retrieve the correct results including the word "world".
Conclusion
The Levenshtein edit distance is a powerful and versatile metric that quantifies the similarity between two strings by measuring the number of single-character edits needed to transform one string into the other. With applications in natural language processing, bioinformatics, data analysis, and search engines, this algorithm plays an important role in many domains.
Although the naive recursive implementation of the Levenshtein distance algorithm has a high time complexity, the dynamic programming-based approach greatly improves its efficiency, making it practical for a wide range of use cases.
Furthermore, the highly optimized Levenshtein implementation in Orama enables typo-tolerance in searches, enhancing the search experience for users.
In summary, the Levenshtein edit distance algorithm is a valuable tool for comparing and analyzing strings, enabling developers and researchers to build more accurate and effective solutions in various fields.
Run unlimited full-text, vector, and hybrid search queries at the edge, for free!





